《表3 Twitter数据集用来分类的30个高频Hashtag》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
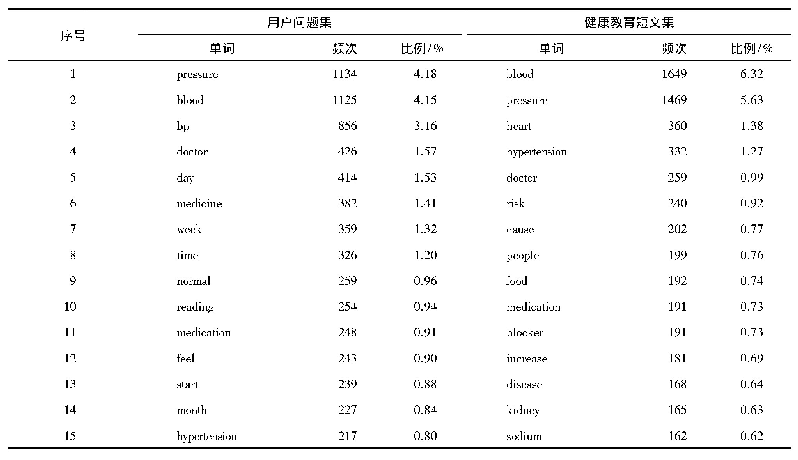
在词向量的选择上,使用谷歌新闻语料训练的词向量,词向量维数为200。在除停用词等无意义的词后,选择Skip-gram算法训练,其他参数为模型默认值,最终生成数据集。同时在数据集中本文采用Twitter提供的主题标签(Hashtag)功能对数据集进行分类(工具采用线性SVM分类器),并提取其中的内容。抽取20个高频的Hashtag作为分类数据的标签。如表3所示。
| 图表编号 | XD003785500 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.12.01 |
| 作者 | 黄婵 |
| 绘制单位 | 赣州师范高等专科学校 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}