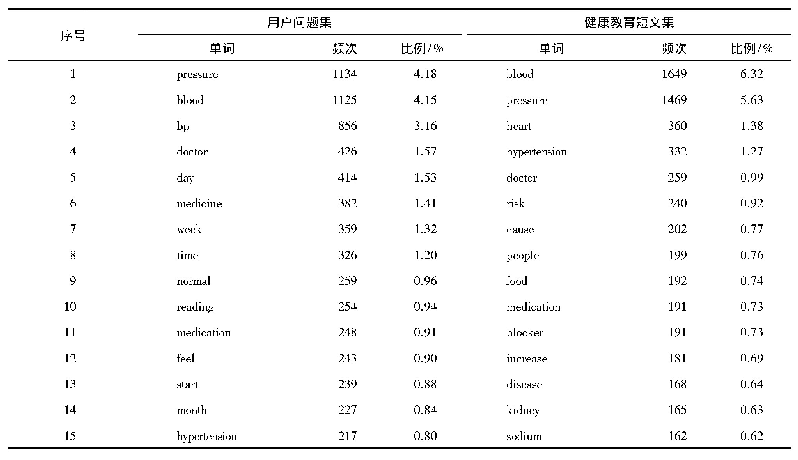
《表2 数据集的前15个高频词汇》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
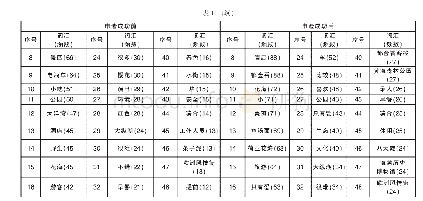
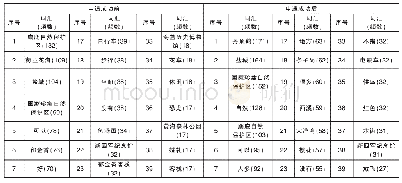
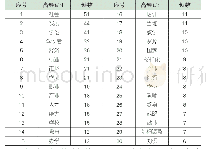
本文数据预处理借助jieba组件、StanfordPOSTagger和Word Net Lemmatizer分别进行分词、词性标注及词形还原,然后去除语料集中的停用词,对两个数据集的词汇分别进行统计,结果如表1所示。经jieba分词后得到用户问题集中的单词总数约为健康教育短文集中的2倍,但在词性标注及词形还原、去重预处理操作后两个数据集中唯一词的数量较为接近。对原始的用户问题集和教育短文集进行Meta Map处理,得到UMLS概念映射数量分别为4810和4427。数据预处理后,各数据集的前15个高频单词如表2所示。
| 图表编号 | XD00215128400 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.10.01 |
| 作者 | 陈育新、安欣宇、刘春鹤、兰雪、张晗 |
| 绘制单位 | 中国医科大学医学信息学院、中国医科大学医学信息学院、中国医科大学医学信息学院、中国医科大学医学信息学院、中国医科大学医学信息学院 |
| 更多格式 | 高清、无水印(增值服务) |
{kind=link}