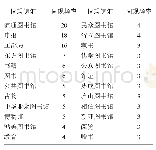
《表2《申报》标题中与“图书馆”同现率最高的前24个词汇》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
(2)基于分布相似度识别等级关系词汇。根据词汇分布规律,语义相似的两个词在特定的上下文中是可以互相替代的[16]。根据该原理,把与词汇W同现率较高的前N个词汇作为其上下文,建立起词汇W的特征向量,就可以通过向量空间模型计算两个词汇W1和W2之间的夹角余弦函数值,来表征这两个词汇的语义相似度[17]。以计算词汇“钱庄”和“银楼”之间分布相似度为例,具体操作方法是:首先,利用《申报》数据库分别抽取抗战期间含有这两个词汇的新闻标题,利用中科院分词系统NLPIR对这两组标题分别进行自动分词和词性标注,利用计算机程序抽取词性为名词和动词的词汇,同时按词频高低进行排列,取词频最高的前N个词作为其特征向量(见表4,此处设N=50)。其次,根据向量之间的夹角余弦函数(见公式1)计算这两个词汇所表征概念之间的语义相似度为24%。语义相似度是一个介于0和1之间的值,该值越大,说明两个词汇之间的语义相似度越高。分布相似度方法能够弥补词素后方一致方法的不足,把字面上无相似特征但语义相似度较大的上下位词和同位词识别出来。
| 图表编号 | XD00156118500 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.08.15 |
| 作者 | 杜慧平、薛春香 |
| 绘制单位 | 复旦大学图书馆 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}