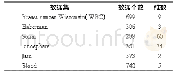
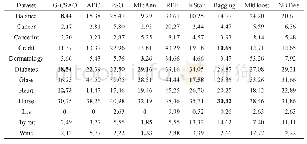
《表4 UCI真实数据集及人脸图像分类结果》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
实验中,对于每一组真实数据集,随机选取样本总数的80%作为训练样本,其余当作测试样本。所有对比算法参数设置作如下介绍:HDCM算法共涉及四个参数,即高级分类方法中的k、dc、γ以及混合分类技术中用于平衡数据物理特征与模式结构关系特征作用的系数λ。由于截断距离dc使得复杂网络中的节点被占节点总数3%~5%的其他节点包围,这里主要设置参数k、γ及λ。根据大量的实验结果,k、γ及λ的取值可分别在{1,2,…,14,15}、{0.1,0.2,…,2.9,3}以及{0,0.1,…,0.9,1}范围内进行搜索,另外,针对参数dc,表1中的真实数据集从上往下分别设置为3.3、0.08、2.9、4.1、0.6、0.2以及0.8。线性SVM中的惩罚系数C取值范围为{2-3,2-2,…,211,212},高斯型SVM的性能除了与惩罚系数C相关外,还与核宽度σ的设置有关,其取值范围为{2-3,2-2,…,211,212}。加权的k近邻算法中参数k的设置与HDCM相同,其分类结果主要取决于测试样本与其所有近邻的加权之和,这里的权值大小为测试样本与其近邻之间欧氏距离的倒数。经典模糊分类方法TSK的数据分类性能主要与模糊规则数R及正则化参数τ相关,实验中这两个参数的取值搜索范围分别设置为{5,10,…,195,200}及{10-5,10-4,…,104,105}。模糊C4.5[6]及对比算法的其他参数均采用默认设置。实验中的算法最优参数均由网格搜索结合5折的交叉验证方法确定,实验数据为运行程序15次后取得的平均结果,分类精度及其标准差、算法最优参数分别表示为**±**(**)。表4给出的混合分类方法最优参数为(k,γ,λ),“-”代表参数的取值为空,表明HDCM中高级分类方法对分类结果未起作用。另外,为了探讨高级分类方法的实际分类性能,表4最后一列给出在UCI真实数据集上单一使用高级分类方法的分类效果,“---”表示无需使用HDCM进行分类。
| 图表编号 | XD0036352500 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.04.25 |
| 作者 | 王惠宇、顾苏杭 |
| 绘制单位 | 常州轻工职业技术学院信息工程学院、常州轻工职业技术学院信息工程学院、江南大学数字媒体学院 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}