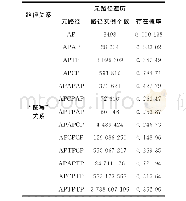
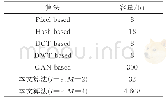
《表2 数据集中每张图像对应的中文标签个数统计》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
为了保证每个标签有足够的训练样本,对于每个数据集,本文经验地保留出现次数不小于20次的词汇,并对其进行人工翻译.经过筛选,Flickr8k-cn和Flickr30k-cn中无中文标签的图像数目分别为9和14.无标签的图像不能用来训练和测试,所以在后续实验中将这些图像去除.表2给出了两个数据集每张图像获得的中文标签的数目统计.
| 图表编号 | XD0035537800 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.01.01 |
| 作者 | 李锡荣 |
| 绘制单位 | 中国人民大学数据工程与知识工程教育部重点实验室、中国人民大学信息学院多媒体计算实验室 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}