《表2 数据中带有中文的表和对应列》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
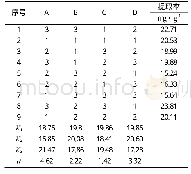
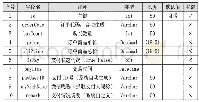
PIC与MIMIC数据库一样包含包括患者的人口统计学、药物使用、体液平衡以及微生物敏感性测试等信息数据,不同之处主要有两点:一是PIC数据库收集了麻醉信息管理系统的患者生命体征数据,每5 min记录一次,生成了新的CSV表格SURGERY_VITAL_SIGNS.csv。二是由于PIC是首个国内全面的儿科患者(0~18岁)重症监护数据,院内许多临床文件和报告都是使用中文记录的,由于无法直接保存叙事性长文本,因此在数据收集的过程中使用了自然语言处理(NLP)的技术从临床进展记录和出院摘要中提取了患者主要症状,生成了EMR_SYMPTOMS表。作者测试NLP模型的平均准确率为91.9%,共生成3410个临床症状。同时为了使PIC数据库能在世界范围内得到广泛使用,数据表内提供了中英双语字典表,不仅使用原始的中文属性记录信息,同时提供了英文的对应代码。数据中包含中文的表和列的具体信息如表2所示。
| 图表编号 | XD00204807900 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.10.20 |
| 作者 | 黄韬、王新宇、冯敖梓、李莉、吕军 |
| 绘制单位 | 暨南大学附属第一医院临床研究部、暨南大学附属第一医院临床研究部、暨南大学附属第一医院临床研究部、暨南大学附属第一医院临床研究部、暨南大学附属第一医院临床研究部 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}