《表2 中文语料标注情况Tab.2 Chinese language annotation》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
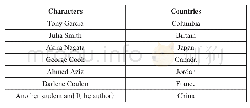
Step1:从原始数据集中提取有效信息,并进行数据清洗。原始数据集是xml数据,包含有文本信息、情感词、当前句距离情感原因词的距离等信息。第一步是要从原始数据中提取到所有的文本(包括中文和英文),以及每段话对应的情感原因句所在的位置,然后对原始文本进行预处理,包括对于标点的处理和对于数字的处理等,接着对文本中的每个词进行对应的标注。就中文而言,得到原始文本经过预处理后,需要对中文进行分词,然后,对每个词分别进行标注,对一个词分别打上2个标签,一个是关于情感原因任务,一个是关于词性标注任务,具体情况如表2。
| 图表编号 | XD0032538100 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.01.25 |
| 作者 | 余传明、李浩男、安璐 |
| 绘制单位 | 中南财经政法大学信息与安全工程学院、中南财经政法大学统计与数学学院、武汉大学信息管理学院 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}