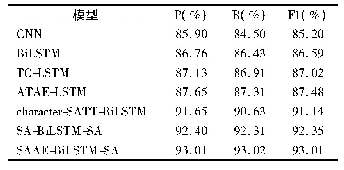
《表5 不同分类模型的性能比较》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《基于计算机视觉技术的茶叶品质随机森林感官评价方法研究》
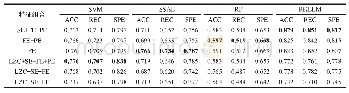
常见模型性能评价指标有识别率、Kappa系数、OOB误差等。Kappa系数是一种度量分类结果一致性的统计量,是度量分类器性能稳定性的依据,Kappa系数值越大,分类器性能越稳定[15-16]。另外,随机森林算法利用OOB误差估计作为对预测误差的无偏估计,评估模型性能,值越小,说明模型精度越高。比较RF模型和SVM模型的总体识别率、OOB误差和Kappa系数,结果见表5。由表可知,随机森林分级模型的总体识别率为95.75%,Kappa系数为0.933,OOB误差为5%;SVM分级模型的总体识别率为92.25%,Kappa系数为0.867。相比于SVM分级模型,随机森林模型的识别率和Kappa系数分别提高了3.5%,0.066。由此可知,茶叶品质随机森林分级模型的识别精度高,其总体识别率和稳定性能均高于SVM模型的结果。
| 图表编号 | XD0032180600 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.01.01 |
| 作者 | 刘鹏、吴瑞梅、杨普香、李文金、文建萍、童阳、胡潇、艾施荣 |
| 绘制单位 | 江西农业大学工学院、江西农业大学工学院、江西省蚕桑茶叶研究所、江西省蚕桑茶叶研究所、江西农业大学工学院、江西农业大学软件学院、江西农业大学软件学院、江西农业大学软件学院 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}