《表3 二分类混淆矩阵:基于改进型深度网络数据融合的滚动轴承故障识别》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
上述准确率是分类正确的样本个数与样本总数的比值,是对模型分类能力和泛化能力的最基本的判断。考虑到实际应用中,故障态样本比健康样本更难收集,不同故障程度的样本也有较大差异,从而导致各个类型样本数量的严重不均衡,此时若单一考量总体的准确率来评估模型,会得到较高的总体准确率,而在一些数据量少的类型上产生严重误差。为客观地评估模型的性能,引入精确率P(Precision)、召回率Re(Recall)、F1(F-measure)值3个分类模型综合评价指标,针对二分类问题的混淆矩阵(表3)可得到计算公式(10)~(12)。
| 图表编号 | XD0030839900 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.02.01 |
| 作者 | 冯新扬、张巧荣、李庆勇 |
| 绘制单位 | 河南财经政法大学计算机与信息工程学院、河南财经政法大学计算机与信息工程学院、河南财经政法大学计算机与信息工程学院、山东大学青岛校区公共(创新)实验教学中心、山东大学信息科学与工程学院 |
| 更多格式 | 高清、无水印(增值服务) |




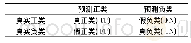

{kind=link}