《表3 二分类混淆矩阵:基于WV-CNN的中文文本语义相似度计算方法》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
准确率(Accuracy)、查准率(Precision)、召回率(Recall)、F1、AUC(Area Under Curve)和ROC(Receiver Operating Characteristic)曲线、KS(Kolmogorov-Smirnov)值都是评价模型好坏的指标,只是评测的侧重点不同,且各指标间有一定的关联。表3是二分类混淆矩阵。
| 图表编号 | XD0033007400 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.01.25 |
| 作者 | 张春英、李春虎、付其峰 |
| 绘制单位 | 华北理工大学理学院、华北理工大学理学院、华北理工大学信息工程学院 |
| 更多格式 | 高清、无水印(增值服务) |



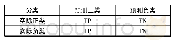

{kind=link}