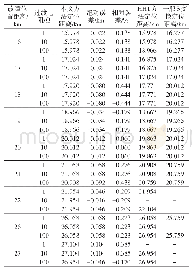
《表4 不同比例训练样本下的故障识别结果Tab.4 Fault recognition results with training samples of different proportions》下
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《优选小波包和AdaBoost-SVM的柔性直流输电变流器故障诊断》
为了比较Adaboost-SVM与传统SVM以及文献[7]中方法的泛化能力,本文从数据样本集中随机抽取不同比例的训练样本,其余作为测试样本。表4是不同比例训练样本下对应的分类识别精度,从表中可明显看出,随着训练样本比例的增大,3种方法的分类识别率也都随之升高,说明训练样本的增加有助于提高故障识别率。当训练样本比例达到50%时,Adaboost-SVM的识别率就已经达到了100%,而当训练样本比例为60%时,文献[7]和Adaboost-SVM算法的分类识别率都达到了100%,说明本文算法在使用较少数量的训练样本就可以达到很高的识别率,泛化能力强。
| 图表编号 | XD0030192000 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.03.01 |
| 作者 | 郑小霞、彭鹏 |
| 绘制单位 | 上海电力学院自动化工程学院、上海电力学院自动化工程学院 |
| 更多格式 | 高清、无水印(增值服务) |



{kind=link}