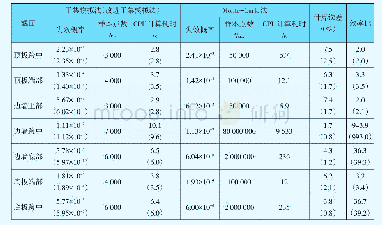
《表1 4 稳健性检查:蒙特卡洛模拟算法》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
注:括号内为标准差。迭代次数为1000次。覆盖率是从实际样本估计的系数和从模拟样本估计的系数之间平等假设未被拒绝的频率。控制变量包含在内。括号内为村级聚类异方差稳健标准误。
我们最主要的担心是可能存在弱工具变量问题使得TSLS估计值偏向相应的OLS估计数值。事实上,TSLS的F检验刚好超过斯托克和雨果(Stock and Yogo,2002)检验20%水平的临界值。为了检验TSLS弱工具变量稳健性,首先,笔者仅仅借助了所拥有的最为有效的工具[也就是E(wfd)/E (wmd)]对等式(14)进行了估算。相应F统计量的值较高,表明这些估计朝OLS的偏误相对较小。相对TSLS,成人物品的系数在量上要更大一些,但在统计学上几乎没有差别。其次,在过度识别的模型中,有限信息极大似然估计值(LIML)以及Fuller-k估计值(α=1)比TSLS受到弱化工具偏差的影响略小,斯托克等人(Stock et al.,2002)对此有所证明。的确,表12中报告的有限信息极大似然估计值与F统计量最低的临界值存在关联,因为F统计量的相应值超过了10%的临界值,所以是最无偏的。正如布罗姆奎斯特和达尔伯格(Blomquist and Dahlberg,1999)所预测,通过LIML的系数比TSLS要略大一些,标准差也是一样,但是估算系数与两种方法之间的差异容易被忽视的事实又强化了工具变量具备足够的预测能力的假设。事实上,如果工具变量为弱工具变量,相较于LIML,TSLS的估计值更接近于OLS的。同样,α=1和α=4的Fuller规则(1)使得F统计量阈值更低,因此比TSLS系数的偏误更小一些,但在量上与TSLS几乎一样。
| 图表编号 | XD0027663300 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.12.01 |
| 作者 | 卢西亚·里奇卡 |
| 绘制单位 | 意大利银行经济统计和研究中心 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}