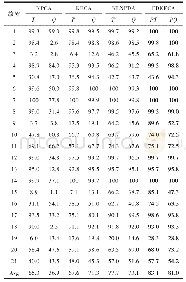
《表2 TE过程不同方法的故障检出率》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
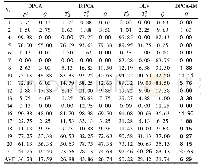
通过对不同的特征数量L进行分析,每个特征数量采用十次平均试验,得到训练平均故障检出率、测试平均故障检出率、训练平均误报率、测试平均误报率、训练和测试总运行时间的结果如图4、图5所示。从图4可以看出,随着特征数量的增大,其测试检出率和训练检出率均先增大后基本保持平稳,说明该方法具有一定的故障检出极限能力;同时,随着特征数量的增大,运行时间也不断延长,尤其是特征数量较大(200~400)时,运行时间呈现指数增长,从图5可以看出,随着特征数量的增大,其测试误报率和训练误报率均不断地减小,且标准偏差也在不断变小。综合考虑较高的检出率和较低的误报率、计算时间不要太长以及稳定性好,最终选择L=200作为学习的特征个数。在该特征数量下,测试平均故障检出率为72.10%,标准偏差为0.38%,测试平均误报率为4.77%,总运行时间1328.4 s,研究发现其训练时间占主要耗时,测试样本总耗时仅为1.18 s,可以达到实时预警的处理速度。选取特征数量为200时训练得最好的一次结果来展示其各故障的检出率并与其他方法进行比较如表2所示,从表2可以看出,所提出的方法对故障1,2,4,6,7,8,10,12,13,14,17,18,20均具有较高的诊断精度。对比PCA方法、改进的ICA方法以及KPCA方法[30]可知,故障检出率所提出的方法最好。其中PCA有8个故障检出率较低,改进的ICA方法有5个故障检出率较低,KPCA方法有8个故障检出率较低,提出的方法有5个故障检出率较低。对于故障3,9,15,由于其本身与正常样本数据的差异性不大,是TE过程中较难检出的故障,因此四种方法的故障检出率都非常低,然而提出的方法却比其他三种方法都高一些,在这方面,或可利用贪婪逐层深度训练以及加入噪声建模等方法,深度挖掘这些微小的扰动性故障与正常的差异性,来提高其故障诊出率。尤其,对于故障10,其他三种方法的故障检出率基本都在70%以下,而本方法高达90.5%,因此,从一定程度上说明本文提出的方法有效地提高了某些难以检测出故障点的性能。
| 图表编号 | XD002560200 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.12.01 |
| 作者 | 江升、旷天亮、李秀喜 |
| 绘制单位 | 华南理工大学化学与化工学院、华南理工大学化学与化工学院、华南理工大学化学与化工学院 |
| 更多格式 | 高清、无水印(增值服务) |



{kind=link}