《表1 不同超分辨重建方法速度对比》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
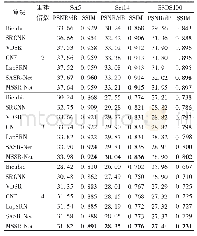
而对于论文中提出的稀疏字典模型[4],假设图像块大小为K×K,字典原子数量为N,上采样倍率为k,那么字典将包含大约(k+1)NK2个参数,而为了保证字典重建的质量,通常原子数超过1 000个.这样庞大的参数数量将会对设备提出很高的要求,通常训练需要若干个小时.而基于传统算法的模型[7]为了追求更好的重建精度,进一步增加了模型的复杂度.基于深度学习的模型[13],由于含有较多的卷积层,每个卷积层又有很多通道,所以需要存储的参数将是所有的卷积层参数之和,模型[13]需要确定的参数在1万以上,使用一块顶级GPU也需要几周时间才能完成训练.无论是传统超分辨算法还是深度学习算法,其模型复杂度都是远远高于本文提出的网络的.本实验中对一块大小为168×168大小的图像进行上采样,采样倍率为3,与当前较优秀的超分辨算法[5]进行比对,不同算法的时间开销如表2,可见本文的算法经过优化,速度比文献[2,5]中的算法更为优秀.
| 图表编号 | XD0023377000 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2018.04.01 |
| 作者 | 马昊宇、徐之海、冯华君、李奇、陈跃庭 |
| 绘制单位 | 浙江大学光电工程与信息学院现代光学仪器国家重点实验室、浙江大学光电工程与信息学院现代光学仪器国家重点实验室、浙江大学光电工程与信息学院现代光学仪器国家重点实验室、浙江大学光电工程与信息学院现代光学仪器国家重点实验室、浙江大学光电工程与信息学院现代光学仪器国家重点实验室 |
| 更多格式 | 高清、无水印(增值服务) |




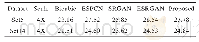
{kind=link}