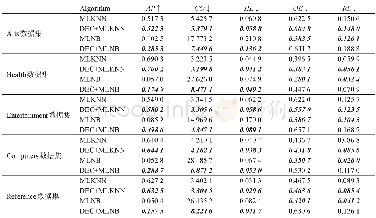
《表2 不同数据集下各方法进行文本分类的F1-score》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
从表2中可总结出:对于同一类型的数据,MSF-MSAI1.75方法构建的向量空间模型较SF-SIDF和SF-SAI而言大幅提升了文本分类性能,结合图2和3可以看出,多语义因子和多层聚类方法的引入均对该性能产生了很大的影响。对于相同数据集中的不同类型数据,由于专业领域不同,各类文本相对于背景语料的词语特征分布会有较大差别,例如CNKI中的Ch类文本在各种方法下的分类情况均相对较差,分析其原因:一方面是由于化学类文本包含太多生僻的化学元素词语导致部分词语分割出现错误;另一方面,本文的背景语料尽管相对于目标文本较多,但并不足以获得比较完善的词距离模型。因此,需要在分词过程中针对不同专业领域尽可能多地加入专业词,并为训练更准确的词向量和部分辅助参数尽可能地扩大背景语料。
| 图表编号 | XD00222767800 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.10.05 |
| 作者 | 王靖、柳青、张德海、赵华、杨云 |
| 绘制单位 | 云南大学软件学院、云南大学软件学院、云南大学软件学院、云南大学信息学院、云南大学软件学院 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}