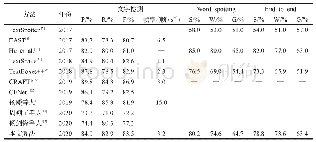
《表1 CNN/Daily Mail数据集实验结果对比》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本文提出的模型在本质上是结合了抽取式模型与生成式模型的思想,所以分别选取目前表现良好的抽取式模型与生成式模型综合比较。论文将对比模型和本文模型统一列出如表1所示,并加以分组,每一列效果最好的模型,用黑色加粗数字标出。实验结果如表1所示,从本文提出的模型可以清楚地看到,在ROUGE-1和ROUGE-L评测中本文模型都超过了所有对比实验模型,说明结合预训练的文本摘要模型是有效的。一方面,相比较于目前比较先进的抽取式Neu SUM模型,本文模型在ROUGE-1和ROUGE-L分数上分别提高了0.77和0.75个百分点。另一方面,与同样使用复制生成模式的Pointer-generator+coverage模型相比、ROUGE-1、ROUGE-2与ROUGE-3都分别提高了2.83、1.6和2.35个百分点。其次,与实验效果较好的生成式Bottom-Up模型相比,ROUGE-1、ROUGE-2和ROUGE-L均有提升,分别提升了1.14、0.2和0.39个百分点。但在ROUGE-2评分上没有达到最好水平,比较于Neu Sum模型相差0.13个百分点。综合以上对比实验,本文提出的结合预训练的文本摘要模型,性能相比单独的抽取式或生成式模型都有一定的提升,达到了最好的效果。
| 图表编号 | XD00222765500 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.10.05 |
| 作者 | 吕瑞、王涛、曾碧卿、刘相湖 |
| 绘制单位 | 华南师范大学计算机学院、华南师范大学计算机学院、华南师范大学计算机学院、华南师范大学计算机学院 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}