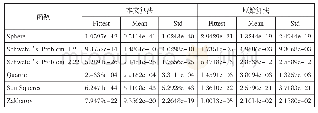
《表1 1 0 个基准函数》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
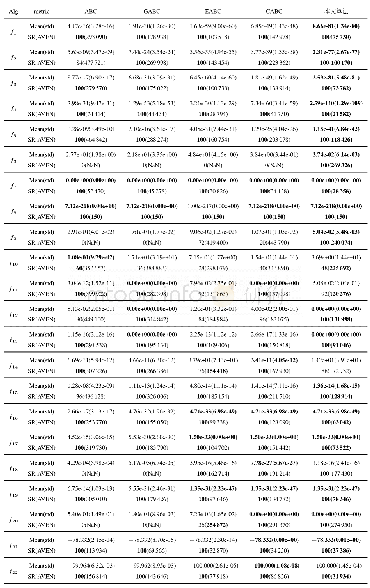
文献[11]中提到一种利用遗传算法中的交叉操作来改进正态分布的分布估计算法,通过交叉操作,使得改进的算法(GA_EDA)的搜索能力得到很大的提升.本节主要对本文中介绍的算法(PSO_EDA)与用遗传算法改进的分布估计算法(GA_EDA)和没有改进的分布估计算法(EDA)进行仿真比较.用表1中的10个计算机实验仿真常用的基准测试函数,从收敛性和求解精度2个角度对3个算法进行客观评估.在参数设置上,为更直接形象地体现算法的优越性,对3种算法的参数进行相同的设置.群体规模设置为100,对于一般问题,群体规模设置为30即可达到很好的效果,而对于较为复杂的问题,群体规模一般设置为100~200,群体规模越大,越容易发现群体的最优解,但运行时间也会增加.学习因子c1和c2是固定常数,早期的实验一般取2,也有的实验采用其他值,但一般都限定c1和c2相等并取值范围在[0,4],本实验的3个算法均设置为2.选择概率指对初步筛选出来的优秀个体进行二次抽样作为随机采样的对象,本实验设置为0.4,既可以保证抽样的范围又可以减少运行的时间.10个测试函数的测试结果分别对应以下图2~图11.
| 图表编号 | XD0021847200 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2018.08.01 |
| 作者 | 赵秋月、高鹰 |
| 绘制单位 | 广州大学计算机科学与教育软件学院、广州大学计算机科学与教育软件学院 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}