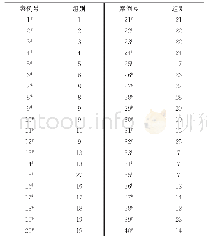
《表6(c) K=4时聚类分析结果》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《基于改进的K-means算法的关联规则数据挖掘研究》
聚类是将数据分类到不同的类或者簇的过程,所以同一个簇中的对象有很大的相似性而不同簇之间的差异性非常大.通过比较表6(a),表6(b)和表6(c),可以看出K值的变化对聚类的影响较小,每个簇内的趋势大致相同.当K=3的时候聚类效果最好,每个簇内的规则间前项都具有共同的特征,且后项相同,簇内的相似性高,不同簇之间的趋势不同.
| 图表编号 | XD00212232000 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2021.01.01 |
| 作者 | 李珺、刘鹤、朱良宽 |
| 绘制单位 | 东北林业大学、东北林业大学、东北林业大学 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}