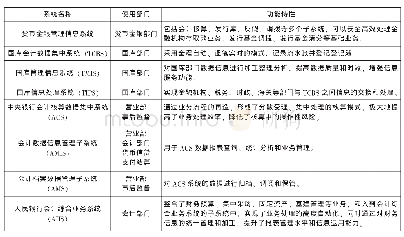
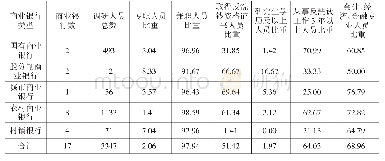
《表2:银行信息系统字符集情况统计表》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
金融行业生僻字是信息系统在存储、传输、显示等过程中无法正常处理的字符,按照产生原因可划分为三种情况:一是采用不同字符集的系统交互导致部分字符无法处理。比如当采用GB18030字符集的应用与采用GBK字符集的应用交互时,由于GBK字符只有21003个,在这范围之外的字符就会无法处理。二是部分字符“一字多码”导致无法处理。“一字多码”的出现主要是因为Unicode的编码空间内存在用户自定义区(PUA),允许自定义编码来处理一些生僻字,这些生僻字后期又被Unicode正式收录,造成一个汉字既有PUA编码又有Unicode正式码的“一字多码”问题。例如“?”字,其在Unicode自定义区编码为“E863”,而其正式编码为“4DAE”。由于GB18030-2005与Unicode编码的一一对应关系,“一字多码”问题同样存在于GB18030-2005编码空间。这部分字大约有3000多个,包括GBK在1995年制定时收录的52个汉字和公安部人口信息系统中收录的方正自定义字中的大部分。三是终端设备字库和常用输入法不支持生僻字。一方面,很多终端设备字库和输入法支持的规范、标准内的字符不全,有的仅支持GBK的21003个字,有的虽然支持GB18030的4字节字符,但不全面,导致终端无法输入、显示和打印。另一方面,公安部人口信息系统中存在大约4700个生僻字,属于方正公司自定义字,需要购买方正字库获得,否则这4700个生僻字终端无法输入、显示和打印。
| 图表编号 | XD00207963700 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2021.02.25 |
| 作者 | 马征 |
| 绘制单位 | 中国人民银行济南分行 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}