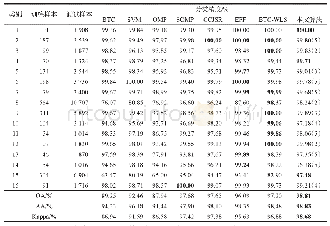
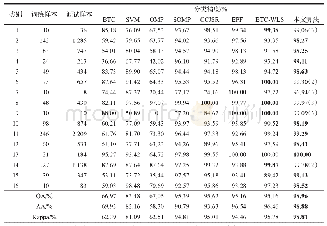
《表5 Salinas数据集采用不同方法的分类精度》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
注:最优结果用粗体表示,括号内的数字表示该类别本文算法分类精度的排名。
对于Salinas数据集,训练样本占5%,测试样本占95%。本文算法与另外7种方法所得分类结果见表5。从表5易见,本文算法在OA、AA、Kappa系数上均是最高的。在16个类别中,除4个类别外,本文算法所得分类精度要么最高,要么与最高分类精度相差不大,至多低0.02%~0.80%。从整体上看,本文算法的分类精度是最优的,分类效果是最好的。和BTC、OMP算法相比,本文算法的OA显著地增加了10%左右;与SVM算法相比,本文算法OA增加了6.5%;与SOMP、CCJSR、EPF、BTC-WLS相比,本文算法OA高出1.1%~1.7%。其他的分类指标AA和Kappa有类似的结果,这说明本文算法具有优势。从图7可以看出,本文算法获得的分类图与参考图更加相符,在葡萄园和酿酒庄园表现得尤为明显。同理,在Salinas数据集继续分析参数k和p,参数(δsx,δrx)以及分类器对本文算法的影响。
| 图表编号 | XD00201555200 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2021.02.15 |
| 作者 | 于多、黄永东 |
| 绘制单位 | 北方民族大学图像处理与理解研究所、北方民族大学图像处理与理解研究所、大连民族大学数学与信息科学研究中心 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}