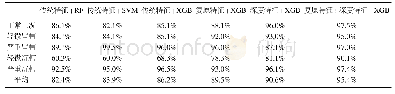
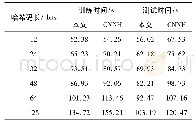
《表3 不同工况识别方法的时间复杂度比较》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《基于复原图像特征与深度视觉特征融合的锑粗选异常工况识别》
由于SVM借助二次规划来求解支持向量,而求解二次规划涉及阶矩阵的计算(为样本数),当较大时该矩阵的存储和计算将耗费大量的机器内存和运算时间.同时,SVM在多分类问题中,需要通过组合多个分类器来解决,在一定程度上增加了运算时间复杂度.随机森林在决策树训练过程中引入随机行采样和随机列采样.同时,每棵树在构建过程中相互独立,所以可以实现高度并行化,故而时间复杂度优于SVM.相比于前两者,XGBoost在保持随机行采样和随机列采样特性的基础上增加了特征粒度上的并行,即对特征值进行了预排序,实现多线程计算特征增益.同时,XGBoost还增加了近似直方图算法,使树的节点进行分裂时不需要计算每个分割点对应的增益,而是通过直方图算法获得候选分割点的分布情况,然后根据候选分割点将连续的特征信息映射到不同的buckets中,并统计汇总信息,提高运算效率.表3是不同工况识别方法的时间复杂度比较,从前3组实验结果对比来看,XGBoost具有明显优势.
| 图表编号 | XD00201048700 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.06.01 |
| 作者 | 保江、谢永芳、刘金平、唐朝晖、艾明曦 |
| 绘制单位 | 中南大学自动化学院、中南大学自动化学院、湖南师范大学信息科学与工程学院、中南大学自动化学院、中南大学自动化学院 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}