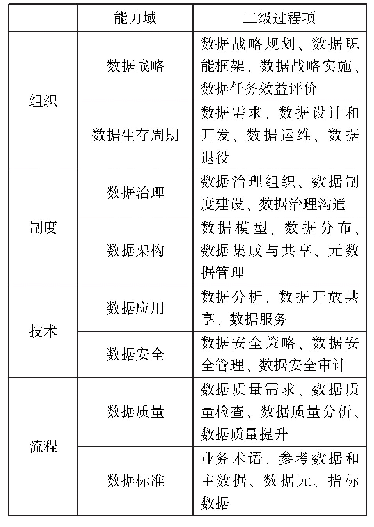
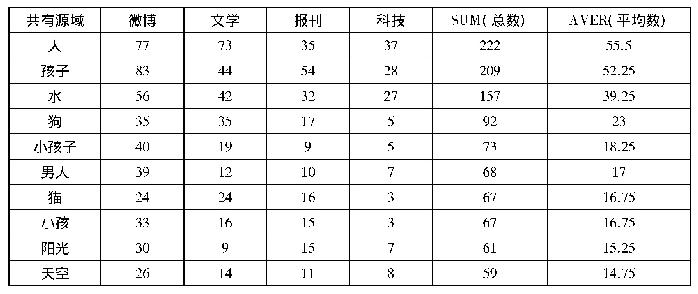
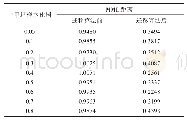
《表1 源域和目标域之间的映射》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《金砖国家形象宣传片的多模态隐喻认知构建——以金砖国家中国形象宣传片《金色未来》为例》
Forceville(1996)在自己的博士论文中提出图像隐喻,并用于广告的分析。随后2009年他大量收集关于多模态隐喻的论文,与Urios-Aparisi共同将其编成《多模态隐喻》论文集。Forceville给模态下定义:“利用人自身的体验过程就可以阐释的符号系统”(Forceville,2009),这就涉及人的感官与模态之间的关系,即视觉模态、听觉模态、触觉模态等。比如,图画、手势需要用到眼睛,是视觉模态、语言、音乐需要用到耳朵,是听觉模态、盲文是触觉模态。然而这个分类是很模糊的,也不够全面。Forceville将模态做了以下9类的详尽划分:“图像符号、书面符号、口头符号、手势、声音、音乐、气味、味道、触碰”(Forceville,2009,ibid:23)。考虑到模态和隐喻的定义,Forceville进一步区分了单模态隐喻和多模态隐喻:“源域和目标域都只通过或主要通过一种模态来呈现的隐喻是单模态隐喻”(ibid.:23);“源域和目标域以不同的模态出现叫多模态隐喻”(ibid.:24)。简单来说,音乐就是单模态隐喻,而音乐的MV是多模态隐喻,涉及听觉模态和图像(视觉)模态。
| 图表编号 | XD00199679500 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2021.01.25 |
| 作者 | 刘艺 |
| 绘制单位 | 上海理工大学外语学院 |
| 更多格式 | 高清、无水印(增值服务) |



{kind=link}