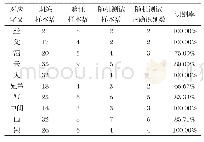
《表2 基于20层Res Net的东巴文字部分识别率统计》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
从图5可以看出训练刚开始时识别准确率提高的很快,且验证数据集与训练数据集同步上升,随着迭代次数的加深,准确率逐渐趋近于98%。由图6损失函数曲线图可看出训练数据集和验证数据集的损失函数随着训练次数加深在逐渐变小,并逐渐趋近于0,由此可以得出:模型训练结果较为理想。获取文字标签,选择非训练数据集中的图像对训练完成的模型进行随机测试,最终输出识别结果,部分识别率统计如表2所示。
| 图表编号 | XD00197624500 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2021.01.01 |
| 作者 | 谢裕睿、董建娥 |
| 绘制单位 | 西南林业大学大数据与智能工程学院、西南林业大学大数据与智能工程学院 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}