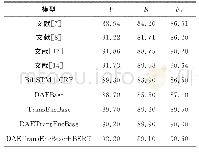
《表3 MSRA数据结果(F值)》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
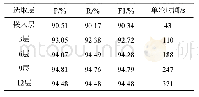
四种模型中对于机构的识别效率均较低,原因主要在于机构名称中存在大量嵌套,且机构名往往较长较为复杂,且容易包含其他性质的词语,因此容易造成歧义。在数据集中出现部分类似“日本伊藤忠商事公司”、“新西兰航空公司”等机构命中包含地名的嵌套现象,同时也会存在“阿航”等机构的简写。经统计MSRA训练集与人民日报训练集中机构类实体数量分别为19575和9831,Bert对其识别的准确率仍能达到90%以上。LSTM由于受其网络模型性能所限,缺乏训练数据表现较CRF仍有2%的差距。MSRA数据集使用了近两倍于人民日报数据集的训练数据,但对于CRF的提升并不明显,而对于神经网络模型却有较大提升,同时使用了Bert预训练字符向量的模型在人民日报数据集上的表现较其他模型在MSRA数据集上的表现更好,即使前者使用了较少的训练数据。为避免因数据集差异造成的结果不准确,接下来的实验将MSRA数据集随机划分出与人民日报数据集相同体量的训练数据,并在四种模型上进行了实验,四种模型F值的表现与未划分前的对比如下图所示,从图中可看出划分后的MSRA数据与人民日报数据在四种模型的表现基本一致,而MSRA完整数据以其较多的训练数据优势在四种模型上的表现均为最好,而使用了Bert预训练字符向量的模型在划分后的MSRA数据集上的表现仍优于其他模型在MSRA完整数据集上的结果。
| 图表编号 | XD00197594000 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2021.01.01 |
| 作者 | 宫义山、段亚奇 |
| 绘制单位 | 沈阳工业大学信息科学与工程学院、沈阳工业大学信息科学与工程学院 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}