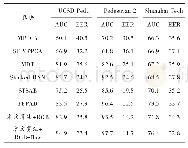
《表1 SIGHAN2005数据集上的F值测试结果(%)》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
SIGHAN2005[11]提供的数据集中包括训练集、测试集以及测试集黄金分割标准,除此之外还提供一个用于评分的脚本。比赛数据由4个数据集组成,分别是简体中文的北京大学PKU数据集和微软研究院MSR数据集;繁体中文的CityU数据集和AS数据集。它们至今仍作为学术界评测分词方法准确程度的重要标准。在这些数据集上评测的最佳F值结果如表1所示,包括比赛评测和后续文献。不同方法的最佳F值基本达到甚至超过95%。单纯设计一种学习算法已很难继续提升分词精度,如何更有效地结合不同算法是未来的研究方向。开放测试除了需要关注算法本身,更好的预训练和后处理对于提升分词结果至关重要。
| 图表编号 | XD00139941000 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.03.25 |
| 作者 | 唐琳、郭崇慧、陈静锋 |
| 绘制单位 | 大连理工大学系统工程研究所、大连理工大学系统工程研究所、大连理工大学系统工程研究所 |
| 更多格式 | 高清、无水印(增值服务) |


{kind=link}