《表1 3D Res Net网络参数》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
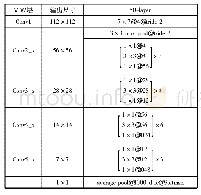
在实验过程中,对于原始的微表情视频序列,本文首先通过TIM模型[17]进行视频归一化,进而统一视频序列的时间尺度。表1是将微表情视频序列帧数统一为64帧时各参数的设置情况,随后微表情视频序列的尺寸统一设置为112×112作为网络的输入。表中还包括了网络整体结构中卷积核、步长、通道、各网络层以及输出尺寸等参数的设置。其中S1和S2分别表示设置的时间步长及空间步长。首先通过对原始的微表情序列进行4×4×4时空卷积。随后经过第一次三维卷积后图像的输出尺寸缩减为16×56×56,接着是它的一个残差块结构,每一个大的残差块里有两个残差单元。引入残差单元可以让浅层的特征在深层继续被重复利用,并且残差块内的卷积都是采用1×1×1和3×3×3的小卷积核进行的卷积运算,能够较好地学习微表情中变化微弱的特征信息。训练阶段设置网络的学习率和正则化率统一为0.001,epoch次数(所有训练样本训练次数)设置范围为30~50,batchsize(每批样本的大小)设置范围为5~10。在后期训练过程中还需不断地观察输出损失值的变化,再根据输出的损失值,以10倍速率慢慢降低学习率。当输出的损失值达到一个足够低的水平且不再下降时,就及时停止训练,通常这时模型能达到一个较好的拟合效果。
| 图表编号 | XD00197071500 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2021.01.01 |
| 作者 | 方明、陈文强 |
| 绘制单位 | 长春理工大学计算机科学技术学院、长春理工大学人工智能学院、长春理工大学计算机科学技术学院 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}