《表2 信用评价模型的效果》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
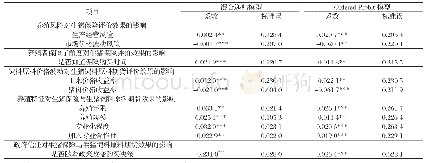
选择两种广泛应用在信用评价问题中的智能学习算法,SVM和DT,作为Adaboost集成算法的基分类器,构建集成信用评价模型,并用以检验跨业务特征在信用评价过程中的作用。在基于Adaboost的集成支持向量机模型中(Ada+SVM),分别运用RBF和Poly核函数构建评价模型;在基于Adaboost的集成决策树模型中(Ada+DT),分别运用GainRate(GR)和Gini分裂规则构建评价模型。实验结果如表2所示。由表2可知,总体上,加入跨业务信用特征(Fa+Fb)所构建的信用评价模型比单纯依靠借贷业务信用特征(Fa)构建的信用评价模型具有更好的分类效果。仅有当使用GainRate分裂规则构建集成决策树模型时,加入跨业务信用特征使得第一类错误(Type I)的比例略微上升(0.321>0.319),然而第二类错误(Type II)的比例仍下降明显。由于第二类错误的误分类成本更大,因此加入跨业务信用特征仍使得该模型的整体犯错代价显著降低。该模型的AUC值也表明,加入跨业务信用特征使得分类的整体效果更好(0.701>0.688)。
| 图表编号 | XD00194467400 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.07.20 |
| 作者 | 梁坤、何军 |
| 绘制单位 | 安徽大学商学院、安徽大学商学院 |
| 更多格式 | 高清、无水印(增值服务) |


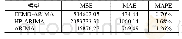


{kind=link}