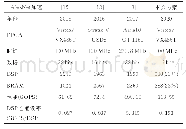
《表5 与其他加速器在Alex Net卷积层加速效果对比》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
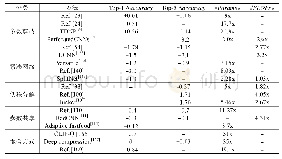
将提出的加速器在卷积层的加速结果与其他文献中的结果进行对比,其中Alex Net卷积层加速效果对比如表5所示,与VGG-16卷积层加速效果对比见表6.在Alex Net加速性能上,提出的加速器与文献[12-13]相比,本文加速器并行程度高,对不同尺寸卷积核适应性强,加速性能较好;与文献[8]的三维11×14×8计算阵列相比,规模与时序均有不足,性能存在差距.在VGG-16加速性能上,加速器与文献[13]相比加速效果较好,与文献[14]的加速性能基本一致,与文献[15]相比存在差距,存在差距的原因在于计算阵列规模与时序上有不足.在BRAM的使用上,本文加速器充分进行多种类型数据复用,优化片外访存,BRAM的资源使用量远小于其他文献,和内存资源消耗少的文献[14]相比,BRAM使用量节省41%.由于FPGA开发平台在工艺与资源上存在差别,在DSP性能效率上本文提出的加速器比文献[12-15]有更优异的性能表现,DSP性能效率提升33%.与文献[8]的加速器相比,本文加速器DSP性能效率在Alex Net加速上存在差距,主要是时钟频率差距带来的影响,但在BRAM使用上比文献[8]节省了约80%的内存.综上,本文提出的加速器从DSP性能效率与内存资源使用上看,综合表现优于当下的加速器,适合在移动端实现硬件加速.
| 图表编号 | XD00192292200 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.07.30 |
| 作者 | 梅志伟、王维东 |
| 绘制单位 | 浙江大学信息与电子工程学院、浙江大学-瑞芯微多媒体系统联合实验室浙江大学信息与电子工程学院、浙江大学信息与电子工程学院、浙江大学-瑞芯微多媒体系统联合实验室浙江大学信息与电子工程学院 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}