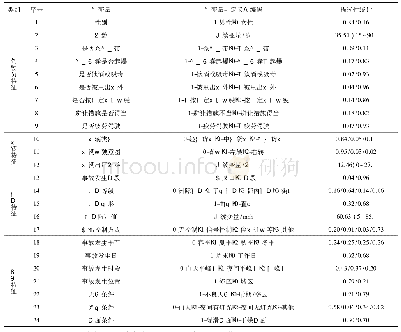
《表1 自变量的定义与描述性统计》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《基于混合有序Probit模型的货车翻车驾驶员伤害程度研究》
注:对于离散变量,描述性统计是指频率统计,编码为0的类别为参考类别,离散变量在进行模型拟合时需将其转化为0-1变量;对于连续变量,描述性统计是指均值、最小值、最大值统计,第一个值为均值,括号内为最小值与最大值;由于车辆实际出厂年份的最大值为2017,故将2017年设定为
考虑到货车翻车单车事故(仅涉及一辆货车的翻车事故)与货车翻车多车事故的发生机理相差甚大,并且翻车货车多车事故的发生比例较低,故笔者只考虑仅涉及一辆货车的翻车事故。在正式分析数据前有必要对原始事故数据进行数据清洗,包括剔除不合理(如驾驶员年龄过小)、干扰的数据(非货车事故)和不完整的单条事故记录。经过数据预处理,最终保留3 476起翻车货车事故作为研究对象,选取驾驶员、车辆、道路以及环境特征共24个安全因素为自变量,见表1。因变量为驾驶员伤害程度。美国Texas州的事故采集标准将驾驶员伤害程度根据严重性从高到低划分为5个水平,依次为死亡、失能伤害、非失能伤害、可能受伤、未受伤。由于死亡和失能伤害的比例非常低,故将这两个类别合并为失能性伤害或死亡。失能伤害或死亡、非失能伤害、可能受伤以及未受伤的比例分别为8.52%、19.94%、15.33%以及56.21%。
| 图表编号 | XD00190742000 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2021.02.01 |
| 作者 | 李俊辉、汤左淦 |
| 绘制单位 | 广东交通职业技术学院轨道交通学院、深圳市城市交通规划设计研究中心股份有限公司 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}