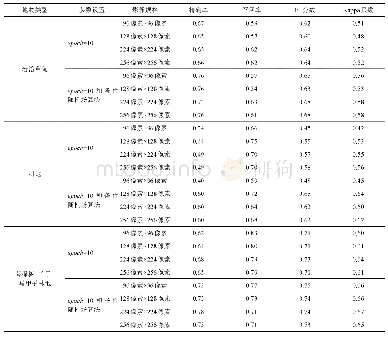
《表2 使用NYU Depth V2数据库对动态密集条件随机场和其他机器人语义SLAM方法进行对比》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《基于动态密集条件随机场增量推理计算的多类别视频分割》
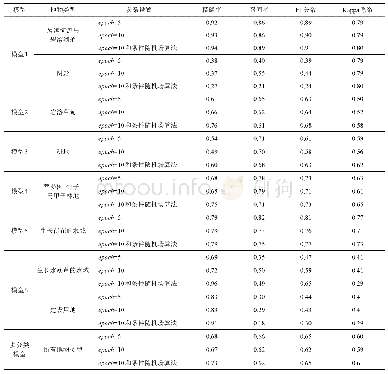
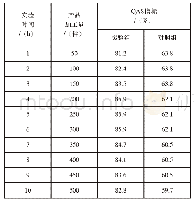
本实验采用动态密集条件随机场算法对每个场景进行语义分割的增量式优化处理,并从19 880张关键帧优化结果中取出对应的654张测试集图片用于精度对比。其中,Deep Lab V3+表示仅使用Deep Lab V3+神经网络进行训练得到的测试集中单张图片的语义分割结果;Deep Lab V3++dynamic dense CRF表示基于Deep Lab V3+得到的关键帧一元势能,并通过动态密集条件随机场优化所有关键帧构建的语义地图得到的测试集语义分割结果;Hermans表示Hermans等人[42]的实验结果;RGBD-SF-CRF表示Mc Cormac等人[44]提出的Semantic Fusion方法结合条件随机场得到的结果,但需要指明的是,Mc Cormac等人仅仅使用了NYUDepth V2数据集中的一个子集(因为部分场景跑丢)。Hermans和RGBD-SF-CRF结果忽略了缺少深度信息的像素。每一类的精度、像素精度(PA)、均像素精度(MPA)和均交并比(MIo U)结果如表2所示。
| 图表编号 | XD00189247600 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.12.05 |
| 作者 | 张晓翔、卢先领、周洪钧 |
| 绘制单位 | 江南大学物联网工程学院、江南大学物联网工程学院、同济大学 |
| 更多格式 | 高清、无水印(增值服务) |



{kind=link}