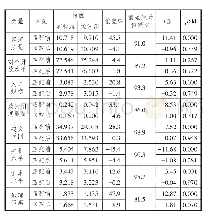
《表2 可观测变量匹配前后平衡性检验结果》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
注:实验组为“一带一路”沿线国家,控制组为非“一带一路”沿线国家。
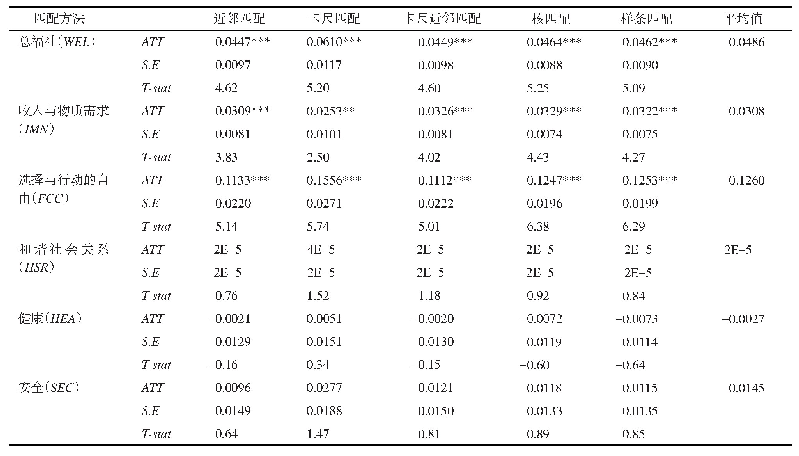
由于中国与世界各国的双边贸易额差距较大,存在较为明显的差异性,直接使用双重差分法会造成估计偏误,本文借鉴赫克曼(Heckman)等[21-22]提出的得分倾向匹配双重差分法(Propensity Score Matching Differences in Differences)进行处理,采用得分倾向匹配的方法减少样本选择上的偏差,然后再采用双重差分法进行模型估计。得分倾向匹配的基本原理在于在控制组中匹配某个国家,使其与实验组国家的可观测变量最大程度地接近,缩小实验组和控制组国家之间的差异性,进而修正样本选择中的偏误,然后再使用匹配后的处理组和对照组进行双重差分分析。模型中可观测的控制变量采用近邻匹配的方法,对实验组和控制组进行匹配,采用Logit来估计二者的倾向得分。从表2中的结果来看,各观测变量匹配前实验组和控制组之间的差异较大,匹配后实验组和控制组均值偏差的绝对值都在10%以内,各变量偏差绝对值明显变小,这表明得分倾向匹配大幅度减少了实验组和控制组观测值均值之间的差异性,符合可比性的要求。
| 图表编号 | XD00179162700 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.07.15 |
| 作者 | 周建军、于爱芝、李一丁 |
| 绘制单位 | 中央财经大学经济学院、中央财经大学经济学院、中国政法大学商学院 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}