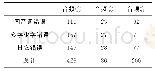
《表1 错误识别量及纠错量统计表》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《基于翻译教学的评价语料库与译文质量评估的实证研究》
注:学生译文栏目中的第1个数字表示评判员识别出的错误数量,第2个数字表示译员根据反馈意见改正的错误数量,如学生译文1的数字为12/8,这表示评判员的识别错误数量12,译员的改正数量为8。
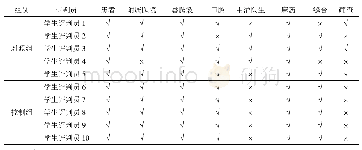
测试的实验数据包括学生评判员(以下简称评判员)在译文中标注的错误数量以及学生译员(以下简称译员)根据评判员的反馈意见改正的错误数量,如表1所示。相同词汇错误识别的统一性,即评判员是否能在英文译文中识别出某一汉语医学术语并判别其翻译的正确性,如表2所示。为了保证测试的客观性,选取了由翻译软件trados(塔多思)萃取出的术语,表2栏目中所列举的8个医学术语只是源文诸多术语中的一部分,为随机筛选的结果,非特别圈定的测试内容,也并未提前告知被测试人员,这样做的目的是测试评判员和译员是否能真正识别术语并给出正确译文。
| 图表编号 | XD00174198200 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.07.25 |
| 作者 | 王红玫 |
| 绘制单位 | 温州大学外国语学院 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}