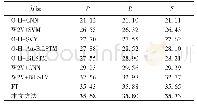
《表4 不同词向量维度的模型实验结果》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
词向量能够有效地反映词与词之间的关联度以及语义信息,理论上来说词向量维度越大越好,但实际应用中需要考虑实验的整体性能和整体代价,从而选出最合适的词向量维度。表4为不同词向量维度的模型实验结果,由表4可知,当词向量维度为50时,模型的整体性能最差,主要是因为词向量维度过小,使得词中包含的上下文相互影响的语义信息较少;当词向量维度为200时,模型的整体性能最好,训练的时间相对较小,主要是因为词中上下文的关联度比较大,包含更丰富的文本语义信息。因此本模型把词向量的维度设置成200。
| 图表编号 | XD00173719100 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.08.28 |
| 作者 | 孙敏、李旸、庄正飞、钱涛 |
| 绘制单位 | 安徽农业大学信息与计算机学院、安徽农业大学信息与计算机学院、安徽农业大学信息与计算机学院、安徽农业大学信息与计算机学院 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}