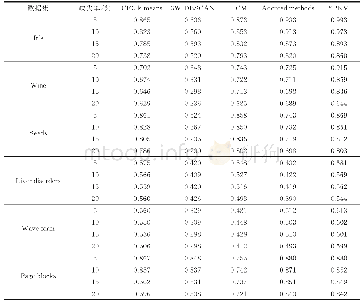
《表7 5种算法在指标FMI下的对比结果》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《一种面向不完备信息系统的集对k-means聚类算法》
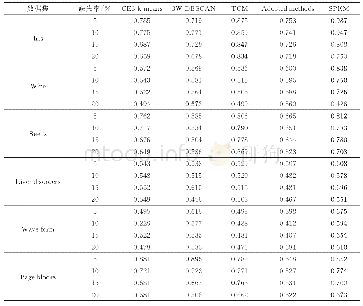
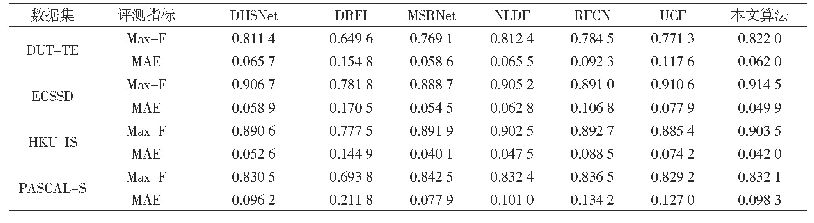
从表5的实验结果可以看出,对于数据集Iris,Wine,Liver disorders和Wave form,用评价指标Macro F1得到的聚类结果要明显高于对比算法,也体现出了SPKM算法的优越性。对于其他两个数据集也得到了不错的聚类结果,比如数据集Seeds,在缺失率为15%的情况下,即使它不是最好的算法,但在缺失率为5%,10%和20%时,Macro F1值要高于其他4个对比算法。从表6中的实验结果可以看出,对于数据集Iris,Wine和Wave form,用评价指标JC得到的聚类结果均优于对比算法。从表7中的实验结果可知,在4个缺失率下数据集Liver disorders和Wave form得到的聚类结果均优于对比算法。从表8的实验结果可知,对于数据集Iris和Wine,用评价指标ARI得到的聚类结果要明显高于对比算法。综上所述,本文提出的聚类算法可以有效处理含有缺失值的不完备数据集,而且具有良好的聚类性能。
| 图表编号 | XD00170141600 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.07.01 |
| 作者 | 张春英、高瑞艳、刘凤春、王佳昊、陈松、冯晓泽、任静 |
| 绘制单位 | 华北理工大学理学院、河北省数据科学与应用重点实验室、华北理工大学理学院、华北理工大学迁安学院、华北理工大学理学院、华北理工大学理学院、华北理工大学理学院、华北理工大学理学院 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}