《表1 人员工作统计表:基于耦合度量的多尺度聚类挖掘方法》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
耦合度量相似性(Couple metric similarity,CMS)是一种主要用于非独立同分布的无监督分类型数据集的相似性度量方法[11]。已经存在的度量分类型数据对象相似性的方法有汉明距离(Hamming distance,HM)、图像耦合分析[12]、发生频率(Occurrence frequency,OF)、逆发生频率(Inverse occurrence frequency,IOF)等,常用的算法有K-modes以及K-prototype算法[13]。其中汉明距离对应于基于匹配的相似性度量,使用0和1来表示不同和相同的分类值之间的相似性,发生频率和逆发生频率都是通过不同属性值的发生频率来表示相似性,K-modes算法采用差异度来表示对象间的相似性,K-prototype则是对K-means和K-mdoes的结合,可用于同时存在数值型属性和分类型属性的数据集。文献[14]提出一种非监督耦合分类数据表示框架,用于捕获层次耦合关系;文献[15]利用概念格,提出一种新的动态加权模型来增强概念相似性测度。但这些方法都忽略了不同属性之间的关系。以表1中的数据为例,说明现有的用于分析分类型数据集相似性方法存在的挑战。人员工作统计表中,每个工作人员都由4个属性组成:性别、文化程度、职业和薪资水平。先前提出的一些相似性度量方法只考虑了对象之间的相似性,比如HM,使用HM衡量对象Staff1和Staff2之间的相似性为0.5,Staff2和Staff3之间的相似性也为0.5。但是很明显,同等教育程度和性别下,薪资水平跟职业有很大的关系。通过观察表1中的数据不难发现,文化程度在很大程度上会影响人们的职业和薪资水平,而由生活经验可知,性别对人们的工作性质也有一定的影响,因此同一属性下不同属性值和不同属性之间的关系对分类型数据集的相似性学习有很重要的参考价值。
| 图表编号 | XD00170139600 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.05.01 |
| 作者 | 田真真、赵书良、李文斌、张璐璐、陈润资 |
| 绘制单位 | 河北师范大学计算机与网络空间安全学院、河北师范大学河北省供应链大数据分析与数据安全工程研究中心、河北师范大学河北省网络与信息安全重点实验室、河北师范大学计算机与网络空间安全学院、河北师范大学河北省供应链大数据分析与数据安全工程研究中心、河北师范大学河北省网络与信息安全重点实验室、河北地质大学信息工程学院、河北师范大学计算机与网络空间安全学院、河北师范大学河北省供应链大数据分析与数据安全工程研究中心、河北师范大学河北省网络与信息安全重点实验室、河北师范大学数学科学学院 |
| 更多格式 | 高清、无水印(增值服务) |



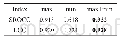

{kind=link}