《表4 评估度量指标:基于数据挖掘技术的财务舞弊识别模型构建》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
在表3中D、C分别代表正确识别负例、将负例识别成正例的数量;B、A则分别表示识别正例为负例的数量与正确识别的正例数量;另外0和1分别指代正事例的未发生与已发生。在该矩阵中,每个类别中被正确识别的样本数量是通过主对角线的数值来体现,而被错误识别的样本数量则是由非主对角线上的数值来表示。在具体应用过程中,通常还结合混淆矩阵特点,通过指标设定方式量化分类器性能,以实现评价分类效果精度提升的目的(见表4):
| 图表编号 | XD0028995400 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.02.20 |
| 作者 | 冯炳纯 |
| 绘制单位 | 广东建设职业技术学院 |
| 更多格式 | 高清、无水印(增值服务) |


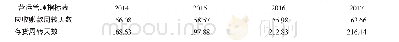



{kind=link}