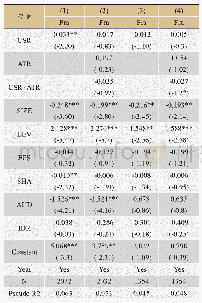
《表5 财务舞弊识别模型评估结果》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
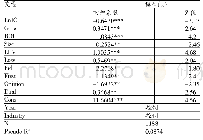
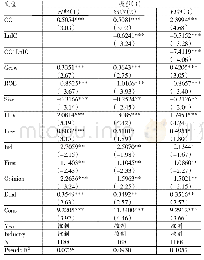
由表5可知,不同指标被同一分类器识别时,支持向量与逻辑回归均具有相对稳定的性能,但两者的F1分值与召回率即识别舞弊公司的能力却较差;随机森林与神经网络则都表现出了不同程度的起伏特性,其中前者是在Boruta算法指标下表现出了更好的识别能力,而后者在Boruta算法指标与初始指标下的结果近似;利用不同分类器对相同指标分类时,逻辑归回、支持向量以及神经网络三者分别与三组指标搭配组合的识别效果均劣于随机森林与三组指标搭配组合的识别效果,随机森林在Boruta算法指标搭配的识别综合性能达到了0.7348,在同种指标体系中占有绝对优势。综合来看,四种算法与初始指标结合而产生的舞弊识别能力较弱,不具备实用意义;舞弊识别效果最好的是随机森林在Relief算法指标中的应用,其召回率达到了75%,处于所有模型中的最优位置。而综合性能最好的模型则是随机森林与Boruta算法指标的搭配,并且该模型的财务舞弊识别能力仅次于随机森林与R elief算法指标的结果。通过以上研究,本文发现流通股比例、流动资产周转率、应收账款周转率、长期债务与营运资金比率、速动比率以及资产负债率6项指标对上市公司财务舞弊行为的影响相对更大。
| 图表编号 | XD0028995600 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.02.20 |
| 作者 | 冯炳纯 |
| 绘制单位 | 广东建设职业技术学院 |
| 更多格式 | 高清、无水印(增值服务) |
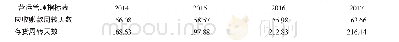

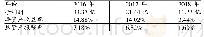
{kind=link}