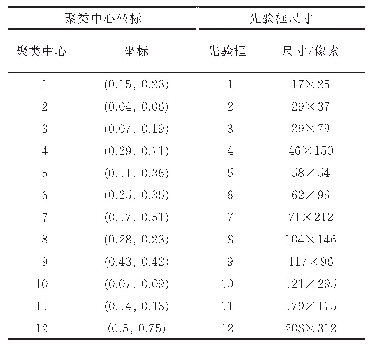
《表1 人脸口罩检测先验框尺寸设置》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《基于YOLOv3和YCrCb的人脸口罩检测与规范佩戴识别》
由于人脸口罩检测的环境比较复杂多样,图像中的人脸大小有大有小,使得精准预测物体位置的难度变大。然而YOLOv3算法的anchor机制能够很好解决该问题。在YOLOv3算法中,每个特征图都被划分成多个单元,每个单元会预测多个边框。通过设置先验框的尺寸,会改变这些单元预测框的大小。总共可设置9种尺度的先验框,在13×13,26×26,52×52的特征图中,分别设置3种先验框,对应地分别适合检测较大的对象,中等大小对象,较小对象。关于这9种先验框尺寸的具体设置,YOLOv3提出的方案是利用K-means聚类算法针对特定的训练集中目标物体大小来确定。在人脸口罩的训练集上,聚类得出的先验框尺寸如表1所示。这样的设置可以检测到绝大多数尺寸的人脸,满足人脸口罩检测各种应用场景的基本需求。
| 图表编号 | XD00168955600 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.07.01 |
| 作者 | 肖俊杰 |
| 绘制单位 | 武汉理工大学计算机科学与技术学院 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}