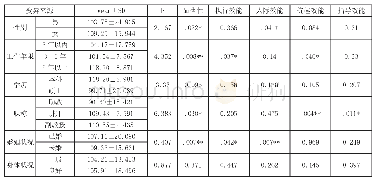
《表1 不同模型的检验效能》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
KNN:(K-nearest neighbor)。
首先将数据按照7∶3分为训练集和验证集,随后计算不同的模型对这一分类任务的效果。特别是由于不同的核函数对支持向量机的影响较大,我们将每一个核函数单列。如表1所示,可见模型效能基于前两位的是随机森林和决策树,剩下的模型检验效能较为接近,其F1-score都在0.8到0.9之间。
| 图表编号 | XD00166706000 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.07.01 |
| 作者 | 陈志远、杨瑞、刘修恒 |
| 绘制单位 | 武汉大学人民医院泌尿外科、武汉大学人民医院泌尿外科、武汉大学人民医院泌尿外科 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}