《表1 数据集描述:基于距离和密度的d-K-means算法》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
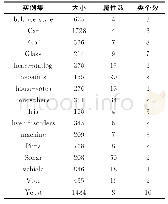
为了验证d-K-means算法在选取初始聚类中心的有效性,选取了专门用于测试聚类算法性能的UCI数据集和美国气象局气候分类数据(weather)。UCI是加州大学提出的用于机器学习的数据库,是一个常用的标准测试数据集,实验数据集中都有明确的分类,因此可以直接观察到聚类的质量。实验对iris、wine、seeds、pima、weather五个数据集进行测试,将BWP指标、兰德指数、轮廓系数、Jaccard系数、迭代次数、准确率作为性能指标,与传统K-means、K-means++、文献[10,11]算法进行比较,表1为数据集的参数情况。
| 图表编号 | XD00163344600 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.06.01 |
| 作者 | 唐泽坤、朱泽宇、杨裔、李彩虹、李廉 |
| 绘制单位 | 兰州大学信息科学与工程学院、兰州大学信息科学与工程学院、兰州大学信息科学与工程学院、兰州大学信息科学与工程学院、兰州大学信息科学与工程学院 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}