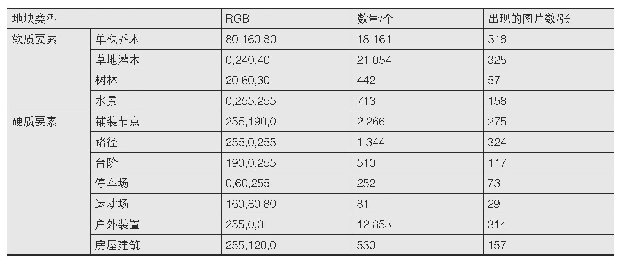
《表3 数据集中各类实体数量统计》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《结合注意力机制的Bi-LSTM-CRF中文电子病历命名实体识别》
3)Jieba分词以及词性标注。Jieba分词是常见的中文分词工具,有中文分词和词性标注等多种功能。在提取实体的过程中,不仅要把实体归入正确的类别中,还要正确识别出实体边界。常用于命名实体识别的标注策略有BIO模式、BIOE模式以及BIOES模式,本文采用了BIOES模式,其中:“B”指的是实体的开始,“I”指的是实体中间的部分,“O”指的是不被标注的实体,“E”指的是实体的结束,“S”指的是实体用单字表示。本实验研究的数据共计335份,其中80%作为训练集,20%作为测试集。训练集和测试集中各类别的实体个数如表3所示。
| 图表编号 | XD00163217200 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.07.10 |
| 作者 | 张华丽、康晓东、李博、王亚鸽、刘汉卿、白放 |
| 绘制单位 | 天津医科大学医学影像学院、天津医科大学医学影像学院、天津医科大学医学影像学院、天津医科大学医学影像学院、天津医科大学医学影像学院、天津医科大学医学影像学院 |
| 更多格式 | 高清、无水印(增值服务) |

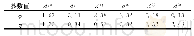
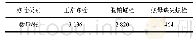

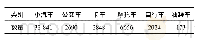
{kind=link}