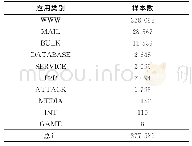
《表3 测试数据集中每个类别的文本数量》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
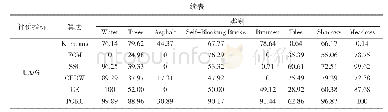
本文从电力行业的科技项目管理系统中提取出了900个科技项目文本作为入库数据集。数据集中每个本文都划分为3个类别中一个,分别是:基础研究、前瞻性研究和应用性研究。表2给出了入库数据集中每个类别的文本数量。其次,采用人工方式新造了10个抄袭科技项目文本组成测试数据集。表3给出了测试数据集中每个类别文本的数量。实验环境是:2核CPU,2.50 GHz,8 GB内存,操作系统Windows 10,Python 3.7,开发工具Spyder 3.2.4。
| 图表编号 | XD00151141100 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.05.06 |
| 作者 | 赵晓平、马文、刘雪萍、陈达 |
| 绘制单位 | 云南电网有限责任公司信息中心、云南电网有限责任公司信息中心、云南云电同方科技有限公司、云南云电同方科技有限公司 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}