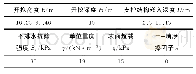
《表1 DSTQN算法中的参数设置》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
在深度强化学习算法中,网络参数对训练的结果有较大的影响,因此参数的设置与调整十分重要。本文针对DSTQN模型所设置的参数如表1所示。其中:折扣因子表示随着训练的不断进行,时间远近对当前训练获得奖励的影响程度;初始学习率是指在开始训练更新策略时更新网络权值的程度大小;训练批次大小指在训练神经网络时每一次送入模型的样本数量;记忆池是用来存储已训练的样本数据的;探索次数是指在探索一定次数后模型开始训练;初始和终止探索因子表示在训练不同阶段探索时选取动作的概率大小。本文采取贪心算法[18]来决定动作的选取,采用一个初始探索因子ε来决定汽车选取动作是随机探索还是根据Q值概率,然后根据训练次数的加大,ε逐渐减小,直到等于终止探索因子ε′时维持不变。根据贪心算法,本文选择最大Q值对应的动作,则能获取趋于最优的自动驾驶运动规划结果。
| 图表编号 | XD00163200900 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.07.10 |
| 作者 | 胡学敏、成煜、陈国文、张若晗、童秀迟 |
| 绘制单位 | 湖北大学计算机与信息工程学院、湖北大学计算机与信息工程学院、湖北大学计算机与信息工程学院、湖北大学计算机与信息工程学院、湖北大学计算机与信息工程学院 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}