《表1 数据集详细信息:面向不均衡数据集的过抽样算法》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
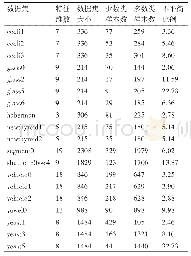
本文实验选用了六个数据集分别为pimax、german3、horseM、breastM、ilpdM、transfusionM。这六个数据集源于不同的实际应用领域,数据集的详细信息见表1,其中样本比率表示多数类与少数类的数目之比,数值越大表明该数据集的不均衡程度越大。在实验中曾尝试在输入数据时采用归一化处理,但是与未采用归一化处理相比较,除了在transfusionM数据集上分类性能略有提升之外,其他数据集上所得分类性能均有较为严重的下降。此外,尝试在子步骤isUse(xj)计算欧氏距离时采用归一化处理,分类性能却略有下降。基于分类性能以及复杂度的考虑,实验中将不再对数据进行归一化处理。
| 图表编号 | XD00163189800 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.06.10 |
| 作者 | 崔鑫、徐华、宿晨 |
| 绘制单位 | 江南大学物联网工程学院、江南大学物联网工程学院、江南大学物联网工程学院 |
| 更多格式 | 高清、无水印(增值服务) |



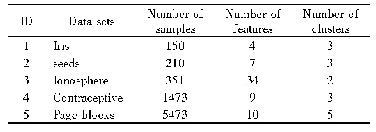

{kind=link}