《表1 基准数据集的详细信息》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
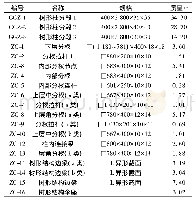
为了评估IGWCA-MR算法的性能,共使用两组测试数据。第一组测试数据来自于UCI资料库,共选取4个典型的基准数据集,分别为Wine、Glass、WDBC、Diabetes,用来评估IGWCA算法的性能。表1给出的是4个基准数据集的详细信息,包括数据量、实际簇数、维度和簇大小四方面的信息。第二组测试数据为真实数据集,共有3组,分别是学生校园卡全年消费记录(Consumption),针对学生全年消费记录对学生的贫困特征进行分簇;另一个是学生选课数据(Selection),根据用户选课情况对学生选课的兴趣偏好进行分簇;最后一个是大学生心理测试数据记录(Psychological),针对全校大学生日常心理测试数据对学生心理表现情况进行分簇。真实数据集如表2所示。
| 图表编号 | XD00219764300 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.10.28 |
| 作者 | 赵彦、孙俊 |
| 绘制单位 | 江苏信息职业技术学院物联网工程学院、江南大学人工智能与模式识别国际联合实验室、江南大学人工智能与模式识别国际联合实验室 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}