《表5 词嵌入投影模型在英语通用数据集上的精准度评测》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
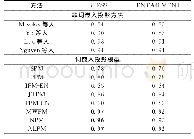
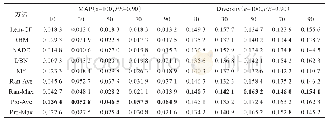
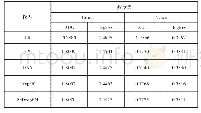
我们在两个公开的中文数据集BK和FD上评测了词嵌入投影模型的预测精度.在这组实验中,我们采用文献[11]的实验设置,将这两个数据集随机分成5等份,分别作为测试集进行5折交叉验证,最后将实验预测结果平均,用Precision、Recall和F1作为评测指标.我们首先利用两个概念词向量的拼接、相减和相加作为特征训练关系预测分类器.他们也在文献[13,45-46]等中作为强基线方法.这些方法在表5中分别记为Concat、Offset和Addition,我们也采用Li等人[24]提出的中文上下位关系预测算法作为基线方法.对于本文提出的算法,IPM的参数设置为t=5,每次选出Top-50个元组作为候选增量数据,加入数据集.在TPM中,我们设置μ1=μ2=10-4,实验细节和参数调整参见文献[11].我们同样调整模型PPM、IPM、JTPM和MWPM中参数K的值,实验结果参见图8.因为中文分类体系的规模一般不大,不适合运用于ALPM的模型,所以这个模型退化为NPM,下文不再讨论.其余模型与中文的语言特性无关,所以我们采取与英语实验相同的设置.实验结果见表7.
| 图表编号 | XD00163168700 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.05.01 |
| 作者 | 汪诚愚、何晓丰、宫学庆、周傲英 |
| 绘制单位 | 华东师范大学软件工程学院、华东师范大学计算机科学与技术学院、华东师范大学软件工程学院、华东师范大学数据科学与工程学院 |
| 更多格式 | 高清、无水印(增值服务) |



{kind=link}