《表2 K均值聚类模型参数》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
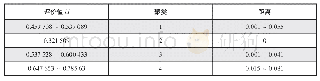
信息时代的到来使寿险公司的营销焦点从产品中心转变为客户中心,客户关系管理成为公司面临的核心问题。客户关系管理的关键是客户分类,即针对不同类型的客户制定个性化营销策略和服务,使得有限资源得到最优分配,进而实现公司利润最大化。聚类分析是对客户进行分类的通用方法,而最常用的聚类算法为K均值聚类。K均值聚类通过迭代算法找到代表数据特定区域的簇中心。算法交替执行两个步骤:第一步,将每个数据点分配给最近的簇中心;第二步,将每个簇中心设置为所分配数据的平均值。如果簇分配不再发生变化,那么算法结束。使用K均值聚类可以在选择合适属性的前提下,实现客户群体的自动分类。K均值聚类模型的参数选取情况见表2。
| 图表编号 | XD00162962100 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.04.20 |
| 作者 | 韩旭东、姚圣煜、王红燕、姚智 |
| 绘制单位 | 国联人寿保险股份有限公司信息技术部、国联人寿保险股份有限公司信息技术部、国联人寿保险股份有限公司信息技术部、国联人寿保险股份有限公司信息技术部 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}