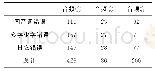
《表2 冻结层微调后语音识别精度》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
%
由表2可知,男性和女性的声音分别测试和合并在一起,与预训练一样,整体准确度的结果对于单独训练的男性和女性声音具有可比性,而男女合并后的精度较低。可以看出,在所有实验条件下,冻结层的百分比为10%~50%时,可获得最佳结果。在90%层被冻结的情况下,根本没有训练成绩。在这项研究中,预训练数据库与实际数据集不相关时,冻结大部分层并只训练最后剩余的层是没有意义的,因为特征的适应度是不够的,可随着冻结层的减少直到某个点改善。由于表1中的结果不充分,无法说明25个学时前培训不充分的假设。在与微调的交互中,只有25个学时阶段的预培训会产生与其他测试案例类似的结果。
| 图表编号 | XD00157004900 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.09.01 |
| 作者 | 张安安、邓芳明 |
| 绘制单位 | 江西省科学院能源研究所、华东交通大学电气与自动化工程学院 |
| 更多格式 | 高清、无水印(增值服务) |


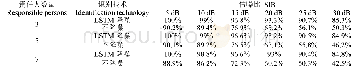

{kind=link}