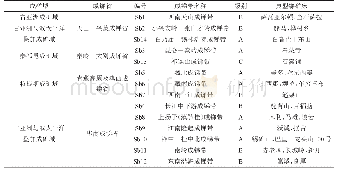
《表1 三种学习技术的算法原则与空间分布规律》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
智能系统之所以能够应用于计算机网络,并达到迭代更新的速度与频次,取决于系统学习能力。当学习能力较高时,经验类型的统计数据也会相对全面,能够为网络执行预案提供多种解析路径。但是当学习能力较弱时,并无法模拟当前最为关键的技术实现方式,因此其可利用价值相对较弱。尤其在适应未知环境的情况下,系统智能化的表现便是学习能力。基于此,后期人工智能的开发也逐步倾向于强化学习的设计方案。目前的人工智能学习技术主要可以划分为3种类型,分别为:强化学习、监督学习、非监督学习。而强化学习模式在应对环境信息时具备了反馈运行机制,能够适应特殊的学习环境更替。当学习环境为内部推理机制提供行为动作指导和,其动作变迁的全新状态反而适应输入条件的运行模式。因此,运行环境在强化学习方法中呈现出及时反馈的信息机制,有助于构建更为完善的学习体系。其运行机制是以奖惩模式而独立存在的动作增强过程,当奖惩条件趋于弱化,动作也会受到干扰,反射出生理学中动作趋势弱化的常规形式。因此,其强化学习模式本身也更加接近于智能化的应用效果,具备较高的实践操作基础条件。依据强化学习运行机制同时开发出了多agent强化学习方案,其运行模式分为3种类型,分别为:合作、平行解、最佳响应。其3种学习技术的算法原则与空间分布规律如表1所示。
| 图表编号 | XD0015600000 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2018.06.18 |
| 作者 | 聂芬 |
| 绘制单位 | 山西水利职业技术学院信息工程系 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}