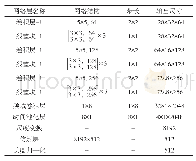
《表1 基于三元组损失的声纹模型网络结构》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
主干网络利用卷积层和多个残差网络中残差单元的组合[13]堆叠而成,整个网络结构的细节如表1所示。每个残差单元由两个卷积核为3×3,步长为1×1的卷积层构成,其中包含低层输出到高层输入的直接映射,3个残差单元的组合结构称为残差块。当输出通道增加时,为保持整体特征的频域维度不变,添加卷积核为5×5,步长为2×2的独立卷积层。语音中能辨识身份的属性大多在频谱的共振峰和包络中,为能学习到更丰富的频域特征,在主干CNN最后添加频域卷积层,使输出的特征图尺寸在频域上的维度为1,且输出通道数仍保持整体频域维度不变。每个卷积层后都加入批标准化(Batch Normalization,BN)和激活层以加快训练速度,激活函数选择上限值为20的线性整流函数(Rectified Linear Unit,ReLU)[14]:
| 图表编号 | XD00155810800 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.07.05 |
| 作者 | 董元菲、王康 |
| 绘制单位 | 武汉邮电科学研究院、南京烽火天地通信科技有限公司、南京烽火天地通信科技有限公司 |
| 更多格式 | 高清、无水印(增值服务) |






{kind=link}